A look at an offline client architecture that I've implemented in an application for a client.
Introduction
This article discusses a disconnected client architecture that I
recently added to a commercial product that I'm developing. Readers
should be aware of the
Smart Client Offline Application Block.
The architecture that I present in this article has similarities.
Because my product already has a rich architecture for communication and
transaction management, I chose an implementation that works closely
with that architecture. You can read about various pieces of that
architecture in the following articles:
DataTable Transaction Logger
DataTable Synchronization Manager
Compressed, Encrypted Network Stream
Job Queue
Simplest Tcp Server
Regarding The Download
The download for this article is not a complete demo application.
It's more like an electronic kit with a PC board and components, and you
need to provide the soldering iron, solder and labor to put it
together. The primary purpose here is to discuss architecture rather
than implementation, so the download consists of the components that you
might find useful to create your own client apps with offline
capabilities.
Offline Challenges
Microsoft's Offline Application Block (OAB) poses some questions
regarding offline challenges, and they seem like a good starting point
to discuss the architecture that I developed.
How does the application determine if it is online or offline?
There are three places where an application determines that it is offline:
- During the attempt to connect to the server
- An exception being thrown while sending or receiving data
- An exception being thrown while in a wait state waiting to read data
During The Attempt To Connect To The Server
The Connect method illustrates the implementation that determines when the connection attempt fails:
 Collapse
Collapse |
public override void Connect()
{
if (tcpClient == null)
{
tcpClient = new TcpClient();
try
{
tcpClient.Connect(host, port);
}
catch (Exception)
{
RaiseConnectionFailed();
tcpClient = null;
}
if (tcpClient != null)
{
InitializeReader();
}
}
}
If the connection fails, the ConnectionFailed event is raised.
Typically, the event handler switches the client into a disconnected
state:
Collapse |
protected void OnConnectionFailed(object sender, EventArgs e)
{
if (!allowDisconnectedOperation)
{
throw new ConnectionException("Connection with the server failed.");
}
if (isConnected)
{
SetDisconnectedState();
disconnectedServerComm.HandleConnectionFailure();
connectedServerComm.StartReconnectThread();
}
}
A thread to attempt reconnection is also started.
Collapse |
protected void ReconnectThread()
{
bool connected = false;
while (!connected)
{
Thread.Sleep(1000);
try
{
tcpClient = new TcpClient();
tcpClient.Connect(host, port);
connected = true;
RaiseReconnectedToServer();
}
catch
{
}
}
}
The ConnectedToServer event is raised when the client successfully reconnects.
Thread Issues
The ConnectedToServer event is raised in a worker thread. This is an
important issue because this event will be raised asynchronously. The
event handler and methods that it calls must be thread safe. I use a
specific object to block execution of communication and the reconnect
process to ensure the smooth transition from a disconnected state to a
connected state:
Collapse |
void OnReconnectedToServer(object sender, EventArgs e)
{
lock (commLock)
{
...
The commLock object:
Collapse |
protected object commLock = new Object();
public object CommLock
{
get { return commLock; }
}
is used during all communications with the server. There is a single
method entry point for sending a command to the server and receiving the
response (incidentally, the "command" is a synchronous process--a
response must be received before processing continues):
Collapse |
public static class IssueCommand<T> where T : IResponse, new()
{
public static T Go(API api, ICommand cmd)
{
T resp = new T();
lock (api.CommLock)
{
api.ServerComm.Connect();
api.ServerComm.WriteCommand(cmd);
api.ServerComm.ReadResponse(cmd, resp);
}
return resp;
}
}
The above method provides a single entry point for all communications
with the server, allowing synchronization with the asynchronous
reconnected event.
Generics
Generics are used to facilitate deserializing the correct response.
Without generics, the caller would need to cast the the return response.
This isn't a big issue, but I feel it improves the robustness of the
code to specify the response class, for example:
Collapse |
ICommand cmd = new LoginCommand(username, password);
LoginResponse resp = IssueCommand<LoginResponse>.Go(this, cmd);
This ensures that
resp is the same type. In other
implementations, you may, for example, put information about the
response type in the command. This would actually be even more robust,
since there would be no possibility of accidentally specifying the wrong
response type.
An Exception Being Thrown While Sending/Receiving Data
A
TcpLibException (this is my own exception) is raised by the communication service when an exception occurs while writing data. The
WriteCommand method raises the
CommandFailed event so that the client has the chance to handle the command in a disconnected state:
Collapse |
public override void WriteCommand(ICommand cmd)
{
try
{
comm.BeginWrite();
CommandHeader hdr = new CommandHeader(sessionID, cmd.CommandId);
comm.WriteData(hdr);
cmd.Serialize(comm);
comm.EndWrite();
}
catch (TcpLibException)
{
RaiseCommandFailed(cmd);
}
}
An Exception Being Thrown While Waiting For Data
The reader thread blocks until data is available. The communication
service raises a TcpLibException if the connection with the server is
lost. The reader thread handles this exception and raises the
ConnectionFailed event:
Collapse |
while (!stopReader)
{
try
{
comm.BeginRead();
ResponseHeader respHdr;
respHdr = (ResponseHeader)comm.ReadData(typeof(ResponseHeader));
IResponse resp = (IResponse)Activator.CreateInstance(
responseTypes[respHdr.responseId]);
resp.Deserialize(comm);
comm.EndRead();
if (resp is SyncViewResponse)
{
SyncViewResponse svr = (SyncViewResponse)resp;
syncQueue.QueueForWork(svr);
}
else
{
lock (responseData)
{
responseData.Enqueue(resp);
}
}
}
catch (TcpLibException e)
{
if (!stopReader)
{
Disconnect();
stopReader = true;
lock (responseData)
{
responseData.Enqueue(new ConnectionErrorResponse(e.Message,
e.StackTrace));
RaiseConnectionFailed();
}
}
}...
Thread Issues
Here the ConnectionFailed event can be raised by:
- a failure when establishing the connection (usually the main thread)
- a failure to write a command to the server (usually the main thread, but could be a worker thread as well)
- a failure to read the response because the connection was lost (the reader thread)
Therefore, the
ConnectionFailed event handler must take into account that it can be called from different thread context.
If the connection can change at unpredictable times, how should the
application components that depend upon the connection state be
notified?
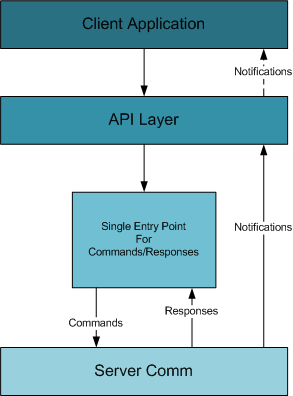
Ideally, the user should continue working with the application
without even knowing that the server went down. This is critical
requirement for some of my clients because the client application is not
something the end user directly interacts with (via a traditional UI,
keyboard and mouse). Other client apps can be running processes that may
take days to complete but communicate to the server frequently for
additional job assignments and report current job status. Even with a
UI-based client application, the idea is to handle the state change
transparently.
This is achieved by having:
- a specific and small set of commands and associated responses that the client can send to the server and receive back
- using a common interface for command and response unifies read/write methods and serialization
- a single point of entry for issuing a command to the server and receiving the response
Typically, the only application component requiring notification is
the API layer, which switches from a connected state to a disconnected
state:
Collapse |
protected void SetDisconnectedState()
{
lock (commLock)
{
if (isConnected)
{
isConnected = false;
serverComm = disconnectedServerComm;
}
}
}
How and where should the application store data locally so that it can be accessed while offline?
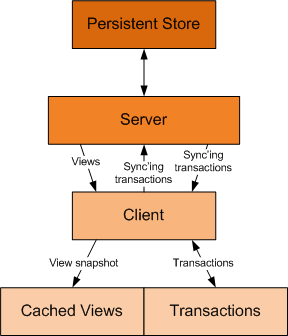
The client application stores data views as a snaphot in a discrete file.
DataView Snapshots
The client works exclusively with discrete DataView instances
provided by the server. These are cached locally using the compression
and encryption technology that I described in my article
Raw Serialization,
and utilize the raw serializer described in my article xxx. So, for
example, to write out a DataView involves the public method:
Collapse |
public static void Write(DataView dv, string name, string prefix)
{
StreamInfo streamInfo=InitializeSerializer(key, iv);
RawDataTable.Serialize(streamInfo.Serializer, dv.Table);
EndWrite(streamInfo);
WriteToFile(prefix + "-" + name + ".cache", streamInfo.WriteBuffer);
streamInfo.EncStream.Close();
}
Initializing the serialization stream:
Collapse |
protected static StreamInfo InitializeSerializer(byte[] key, byte[] iv)
{
MemoryStream writeBuffer = new MemoryStream();
EncryptTransformer et = new EncryptTransformer(EncryptionAlgorithm.Rijndael);
et.IV = iv;
ICryptoTransform ict = et.GetCryptoServiceProvider(key);
CryptoStream encStream = new CryptoStream(writeBuffer, ict,
CryptoStreamMode.Write);
GZipStream comp = new GZipStream(encStream, CompressionMode.Compress, true);
RawSerializer serializer = new RawSerializer(comp);
StreamInfo streamInfo = new StreamInfo(encStream, comp,
writeBuffer, serializer);
streamInfo.Iv = et.IV;
streamInfo.Key = et.Key;
return streamInfo;
}
And writing the data out to a file:
Collapse |
protected static void WriteToFile(string fn, MemoryStream ms)
{
FileStream fs = new FileStream(fn, FileMode.Create);
BinaryWriter bw = new BinaryWriter(fs);
int len = (int)ms.Length;
bw.Write(len);
bw.Write(ms.GetBuffer(), 0, len);
bw.Close();
fs.Close();
}
Technically, I could probably have attached the FileStream to the serializer rather than a MemoryStream.
Can that data become stale?
The data can become stale if it is older than another update that is
done by another client. There is an implicit assumption though that
newer data is more accurate. When synchronizing with server, the
question for the server becomes, is the data I'm getting from the client
stale, meaning that some other client has already updated the record
more recently? ***
When should it be refreshed?
The persistent store is synchronized when the client reconnects to
the server, and the client is synchronized with a new snapshot of the
view after the server is synchronized. Generally speaking, this approach
works well and will immediately update the user's view of the data. The
complexity here is that this may require a client-side business rule to
deal with changes that have occurred in the new view. For example, I
use a notification service to inform the client as to state changes in
an alarm record. When the manager clears an alarm at his station (which
actually updates a row in the database), this automatically sends a
notification to the appropriate client to clear the alarm flag in the
corresponding client hardware. If the client is disconnected, this
notification is not issued. Instead, when the client is resynchronized, a
business rule must fire that compares old data with new data to
determine what alarm flags, if any, need to be cleared.
Should the application behave differently when it does not have access to all the requisite data or services?
To the maximum extent possible, no, it should not act differently. I
have endeavored to ensure that this is achieved. There are several areas
that cause difficulties.
Custom SQL Statements
My product supports custom client-side SQL statements that can be
used in workflows or called directly through the client API layer. For
an offline application, I don't support custom SQL statements. At some
point these might be able to be run on the client but ideally, for any
offline situation, custom SQL statements need to be avoided.
Reports
Reports require querying the server to either generate the report at
the server or to get the DataSet necessary to generate the report at the
client. When offline, reports are not available.
Monitoring And Realtime Notifications
Besides the client behaving differently, the enterprise may be
monitoring whether the clients themselves are offline even though the
server appears to be online. When offline, realtime notifications such
as alarms, income, sensor and hardware status are not possible. This
might be a critical enough issue to the enterprise that other mechanisms
for notification might be needed when offline. Dealing with offline
clients doesn't just involve how the client responds but may also affect
how a monitoring application reports the offline client.
How and where should transactional data (message data) be stored while the application is offline?
There's really two parts to this question. Should the server
implement a transaction mechanism to update offline clients when they
become online, and how does the client manage offline transactions?
Server Transactions--Good Or Bad?
Well, there is no good or bad answer. When designing my product, I
made the decision that the server would not maintain a transaction
queue. Server-side transaction queues add a lot of complexity. How large
do you let the transaction queue get before flushing it and requiring a
fresh reload of the view? How do you track the positions that different
clients may be at within the transaction queue when they connect to the
server? When an offline client synchronizes the server, are you making
sure that the server does not end up re-synchronizing that particular
client? How does restarting the server affect synchronization when the
transaction queue is maintained in memory? If a row is deleted, do you
go through the transaction queue and delete transactions associated with
the deleted row? What if there were client-side business rules that
trigger on those transactions, that might still need to run? Similarly,
if a field is updated, do you delete previous transaction updates? How
scalable is the server architecture when it's maintaining a transaction
queue?
Yes, I could go on and on. None of these questions have right
answers, and sometimes the answer is so application specific that it
seemed to me that maintaining a transaction queue at the server was
actually bad. On the other hand, the "good" architecture now requires
that the client gets a complete snapshot from the server whenever it
requests a view. Potentially, the client could utilize a cached view and
just get the synchronizing transactions. Perhaps this would be less
data, faster, and less of a burden on the persistence server. Again,
questions that cannot be answered generically with the expectation that
the implementation will meet the application specific needs. So in the
end it was the KISS approach that won the day, not the pro or con
arguments for one implementation or another.
DataView Transactions
Ironically, after looking at server side transactions, you will
realize that DataView transactions are managed at the client! In order
to support an offline client, the client must record transactions not
only when offline, but also when online, until the data view is
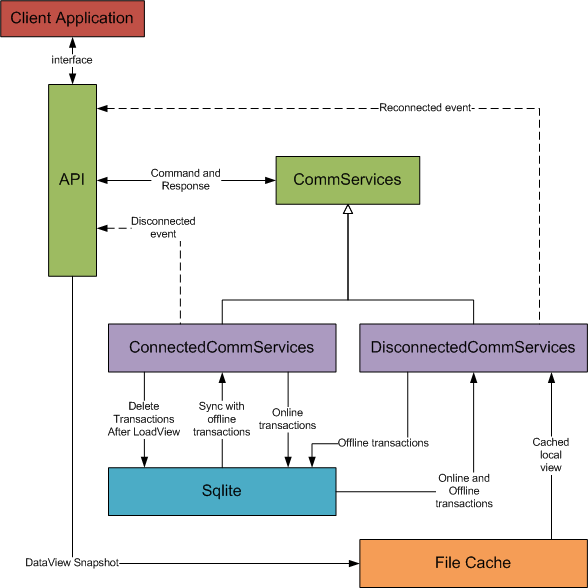
reloaded. The following sequence diagram illustrates the different modes
and how client-local transactions are managed.
When the client is online:

The client:
- Connects to the server
- For a given view, gets offline transactions associated with a view
- Posts them to the server
- Loads the current view from the server, obtaining a current snapshot of the view
- Saves the view to the local cache
- Deletes the offline and online transactions. The view is now current.
- When the client posts transactions to the server, it also saves them as "online" transactions
- Synchronizing transactions sent by the server are also saved as "online" transactions.
When the client is offline:
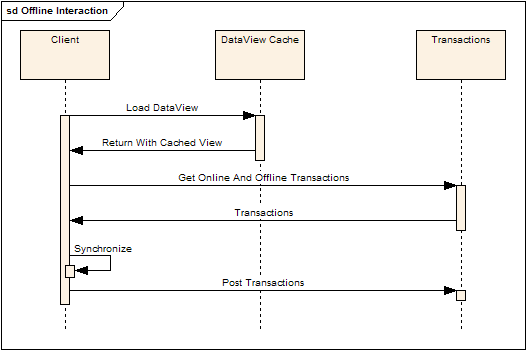
The client:
- Loads the cached view
- Gets both online and offline transactions
- Synchronizes the view with the transactions
- Posts the (offline) transactions locally
Offline transactions are posted using Sqlite:
Collapse |
public void SaveTransactions(PostTransactionsCommand ptc, bool isOffline)
{
StringBuilder csPkList = BuildCsPkList(ptc);
using (DbCommand cmd = sqliteConn.CreateCommand())
{
int id = WriteTransactionInfo(cmd, ptc, csPkList, isOffline ? 1 : 0);
foreach (DataRow row in ptc.Transactions.Rows)
{
using (DbCommand cmd2=sqliteConn.CreateCommand())
{
int recId = WriteTransactionRecord(cmd2, row, id);
foreach (string pkcol in ptc.PKColumnNames)
{
using (DbCommand cmd3 = sqliteConn.CreateCommand())
{
WriteTransactionRecordPrimaryKeys(cmd3, recId, pkcol, row);
}
}
}
}
}
}
The transactions directly correspond to the information that is managed by the
DataTable Transaction Logger. For each transaction set, this consists of:
- The view name
- The primary key column names
In the code, you'll note that the transaction set is qualified not
just by a view name but also by a container name, as the container
concept is used to manage views that my be filtered in different ways.
For each transaction in the set:
- The transaction type (update, insert, delete)
- The column name being affected (not used for insert or delete)
- The value type (not used for insert or delete)
- The new value (not used for insert or delete)
- The PK values that uniquely identify the record (used for all transactions)
How should transactional data be synchronized with the server when the application goes from offline to online?
I feel there's actually two parts to this question--how
and when.
How?
The how is already addressed in the process described above for loading a
DataView--the
offline transactions are sent up to the server, the client gets an
updated snapshot, and the local transactions are deleted.
When?
When is a much more interesting question. For example, for my client,
the application is running 24/7/365 and the computer is contained
within an enclosure. Rebooting or restarting the application is not
desirable, so the client application needs to reconnect and re-sync
automatically. The simpler case would of course be, just re-sync when
the client logs in to the server. This is not a feasible scenario for my
client. On the other hand, if it
is feasible for you, then you can ignore all the issues with reconnecting while running.
When the
ReconnectedToServer event is raised, the client goes through the following motions:
- Sets the client into a connected state
- Logs in
- Reloads the active views
The act of reloading the active views synchronizes the server and
updates the client's view snapshot. The following code illustrates this
process:
Collapse |
void OnReconnectedToServer(object sender, EventArgs e)
{
lock (commLock)
{
RaiseReconnecting();
connectedServerComm.InitializeReader();
SetConnectedState();
Login(username, password);
foreach (Container container in containers.Values)
{
foreach (ViewInfo vi in container.Views)
{
DataView dvNew;
if (vi.CreateOnly)
{
dvNew = CreateViewIntoContainer(vi.ViewName, vi.KeepSynchronized,
vi.Where, vi.ContainerId);
}
else
{
dvNew = LoadViewIntoContainer(vi.ViewName, vi.Where, vi.OrderBy,
vi.DefColValues, vi.Parms, vi.ContainerId,
vi.KeepSynchronized, vi.IsCached);
}
ReloadView(vi.View, dvNew);
}
}
RaiseReconnectFinished();
}
}
The
ReloadView method is a brute force approach to
synchronizing the in-memory DataView with the view that was received
from the server. It really is awful, actually, but it does get the job
done for certain requirements. It uses the
ExtendedProperties feature of the
DataTable class to block transaction logger events and then copies, row by row, field by field, the new
DataView into the existing
DataView.
Collapse |
protected void ReloadView(DataView destView, DataView newView)
{
destView.Table.BeginLoadData();
destView.Table.ExtendedProperties["BlockEvents"]=true;
destView.Table.Rows.Clear();
foreach (DataRow dr in newView.Table.Rows)
{
DataRow newRow = destView.Table.NewRow();
foreach (DataColumn dc in destView.Table.Columns)
{
newRow[dc] = dr[dc.ColumnName];
}
destView.Table.Rows.Add(newRow);
}
destView.Table.AcceptChanges();
destView.Table.EndLoadData();
destView.Table.ExtendedProperties["BlockEvents"] = false;
}
There are several issues with the reconnect process that I discuss in
the "Issues" section below. However, one point here--the above code is
not how to update the
DataView in a production environment. Instead, the
DataView should be synchronized using the existing
DataRow
instances. Care must be taken when dealing with rows currently being
edited (for example, in-grid edits), and editing rows that are now
deleted. The implementation of these mechanisms would itself be worthy
of a separate article.
Question Time
Why Not Use Sqlite For The DataView Cache?
That's a very good question, and it was one that I struggled with for some time. There certainly isn't a right answer.
I decided that I wanted to keep a clear separation between the data
view snapshot and the corresponding transactions. The client doesn't
have any of the logic that the server does with regards to updating
tables, and I didn't want to get to a place where I would even consider
implementing the server side logic to update the client data view in a
client-side database. I would, after all, still need to maintain the
transactions separately so that they could be sent up to the server.
Another reason is that it's simpler. Rather than creating and
managing the necessary tables within Sqlite, it's easier (and faster, in
my experience) to serialize the data view to a discrete file.
And finally, the crux of the matter was the issue of the schema.
While the schema is available to the client, as far as the client is
concerned, the schema is there to help create empty views and access
view properties such as regex validation, which is defined in the
server's schema. The schema though is actually a somewhat dynamic thing.
In many cases, I can update the schema without bringing down the
server. This makes it very convenient to add new functionality to the
enterprise. If I stored the view snapshot in Sqlite as a table, the
client would have to also determine whether the scheme changed, delete
out the old table and create the new one. At the moment, this seems like
unnecessary complexity.
Why Not Use XML For Transactions Instead Of Sqlite?
Another good question. Again, there isn't a right answer. I chose
Sqlite though with the hopes that it would be less verbose than XML and
faster. However, the crux of the matter was that Sqlite provides built
in encryption. If I stored transactions in XML, I would have to provide
the encryption services. Unlike the data view cache, which is a snapshot
and therefore is a one-time encrypt/decrypt process, transactions are
always being added, involve two nested relationships, and need to be
deleted when the server is synchronized. A database seems like a more
natural persistence mechanism than a flat XML file, and not having to
deal with encryption made Sqlite the more logical choice.
Issues
There are several issues with an offline client that must be
addressed by any concrete implementation. These issues are not addressed
in this article.
Authenticating The User
Normally the server authenticates the client. When the client is
offline, the client itself needs to perform the authentication. And of
course, user authentication is entangled with user roles and
permissions.
Roles And Permissions
A simple solution would be to allow only the minimal roles and
permissions when offline. More complicated solutions involve caching the
role and permission tables and implementing the same server-side logic
on the client. Yet again though, what happens if the administrator
revokes a role or permission, but the user continues to have access
because they are offline? How are transactions handled at the server
that now should be disallowed because the role/permissions have changed?
I feel that these are questions that cannot be answered generically and
expect the solution to fit everyone's requirements. On the other hand,
it should be possible to abstract the problem sufficiently to allow the
application to specify the particular paradigm it wants to use, and of
course provide a mechanism to extend that paradigm for requirements that
are truly outside the box (or not considered initially).
Another mechanism might involve specifying which views can be cached
and which views, under no circumstances, are ever cached. Program
features could be disabled as determined by the availability of views
that the feature requires. This is an option but again is specific to
the individual application requirements and can only be supported
abstractly.
Synchronization
Unless explicitly implemented by the client during startup, the
current architecture does not synchronize the server with a data view's
offline changes until that data view is actually loaded. This is
relegated to the client implementation.
Master-Detail Synchronization
Synchronizing a detail view requires synchronizing the master views
first. Or, more generally, any foreign keys in a view are a clue that
there is a parent view that might need to be synchronized first. This is
currently handled by the load order of the views, which is definitely
not the ideal situation. These are issues that this architecture does
not address and is relegated to the client implementation.
Dirty Data
When synchronizing offline transactions (and even during online
operation), it's possible to end up updating a record that has been
deleted or updating a value that has been changed by another client.
These are issues that this architecture does not address and are
relegated to the specific client/server implementation.
Server-Side Qualifiers
To reduce the amount of data being sent from the server to the
client, and to make queries more efficient, we often resort to using
serer-side qualifiers (SQL "where" clauses) to filter the view at the
server. In an offline client, where the view is cached, server-side
qualifiers that filter on client-side dynamic data will fail when
working with a cached view. Examples include:
- The user name or user ID to determine permissions
- UI data that is used to qualify a load view command
These scenarios (and others) add a great deal of complexity to
working with an offline client. The application requirements have to
weigh the issues of data size, performance, and available offline
features, while the developer has to also be very conscious of how they
are interacting with the server and how that might result in preventing
an offline client from actually working (or, even worse, give an offline
client permissions that they would not normally have).
Reconnecting
As I mentioned previously, some of these issues are because of the
requirement to re-establish the connection with the server without
having to restart the client application. If that's not a requirement
for your application, then life becomes a lot easier. That said, here's
some considerations for automatic re-connecting while the application is
running.
What happens if the server goes down during the reconnect process?
The critical issue here is, did the server get the transaction and
can the transaction now be deleted from the client's transaction cache?
Secondarily, how is the client transitioned back to a disconnected state
smoothly? Ensuring that the local DataView cache is not corrupted is
also critical.
What happens if the user is editing a record when a reconnect occurs?
Using the
Row Transaction Sandbox
(RTS), the user can be fairly well isolated from the view update
process--while they are working in the sandbox, the view can be reloaded
without the user losing their edits. Because the RTS itself uses a
transaction logger, committing the changes is not affected by the fact
that, in the above implementation, the concrete
DataRow is
now a new instance. However, if the row is now deleted, or the user in
doing in-grid edits, the RTS does not come to the rescue. Again, the
code presented above for synchronizing the
DataView is a simple hack to get a prototype working.
How are inactive views updated, and when?
In addition to updating views that are currently loaded and possibly
being displayed, the issue remains as to how inactive views are
synchronized. Should this be a background task? Should one not even
bother until the view is needed? Where is the balance in keep the client
as synchronized as possible, dealing with bandwidth considerations (do
you sync a client if they are on a slow connection?) and again other
unpredictable application specific issues and requirements.
The Code
The download, as I've mentioned, is really a toolkit to explore one
way of implementing a disconnected client and as a basic for considering
more complex issues. You will note in the download that the server
command processing implementation is completely missing (though the
TcpServer code is included). You're essentially on your own for creating
the server command processing. I felt that going into the server
implementation would detract from this article, which is focusing on
just the client side. I imagine there will be some people that grumble
about this and the fact that I'm not providing a complete demo. If
encouraged, I may write a follow up article for the minimal server
implementation.
The code consists of the following folders, which I'll describe here:
Api
This consists of the core Api methods that an application would
interface with to communicate with the server. The API architecture
emphasizes that the application use a single interface for communicating
with the server, and the API itself uses a single entry point for
issuing commands and obtaining responses. The API also handles the
connect/disconnect events (among others).
Cache
Has a simple static class that implements file-based caching.
Client
Provides basic and stub implementations that an application client
would need to enhance. A simple template for synchronizing the client
with server notifications is provided, as this is illustrative of the
transaction logger and synchronization manager.
Comm
Implements the template connected and disconnected communication
classes. This includes a complete reader thread and packet reader for
the connected communication class. The disconnected communication class
implements the transaction logging to Sqlite, a thread for attempting
reconnects, and simulating message responses by working with the cached
view data.
Crypto
Implements a wrapper for common encryption algorithms. This is a thin
wrapper for constructing different encryption/decryption algorithms.
Logger
Includes the files for the transaction logger and synchronization
manager. Please refer to the links listed at the beginning of this
article for further documentation. The code here is however the most
current code.
Misc
Miscellaneous classes--a data converter (similar to
Convert.ChangeType), the
KeyedList class, Stephen Toub's managed thread pool class, my
ProcessQueue class, and a string helper class.
Packets
These are the basic command and response packets--login, load view, create view, post transactions, and sync view.
RawSerializer
The raw serializer code, as per
this article.
TcpLib
The communications services classes, covered
here and
here.
Conclusion
This article is not the typical "here's a canned solution to a
problem" article. Instead, I have attempted to discuss the issues
surrounding an offline client architecture, the design decisions that I
made within the context of other articles that I have written, and I
have tried to identify issues that I felt were outside of the scope of a
generic implementation and must be dealt with according to your
specific needs. As I mentioned in the introduction, the code is not a
turnkey solution but more like a kit that hopefully gives you some
useful pieces to play with.
Download source code - 112 Kb .png)










1 comments: